
Imagine that you and your team spent months training, fine-tuning, and tweaking your Deep Learning models to make them accurate, general, and robust. You achieved top-tier metrics, and your test results are looking great. Good job!
Now, how do you deliver all this value to your customers?
This particular question arose in Crisalix some time ago, and let me tell you, it’s a tricky one.
Besides the obvious, this question brought some subsequent queries in matter of infrastructure, software architecture, and much more. How do we serve models written using different frameworks? How is our application architecture going to change? How can we have a standard way of deploying models? How should our infrastructure change to accommodate all of this? In this blog, we present a short introduction to our approach to solving this problem.
Background
In the field of Deep Learning, the models are developed mainly using one of two frameworks or libraries: PyTorch and TensorFlow. However, several companies have a model repository composed of a mix of models written using each of them and the reason is very clear: TensorFlow was there a little bit earlier, but PyTorch has become the industry gold standard.
Each of these frameworks has a way of serving models:
- TensorFlow Serving: A flexible, high-performance serving system for machine learning models, designed for production environments.
- TorchServe: A performant, flexible, and easy-to-use tool for serving PyTorch models in production.
These serving solutions can serve models from different frameworks, but TensorFlow Serving is not particularly fast, TorchServe is not particularly easy for models other than Torch models, and the need to maintain at least two exporting methods for the models looks like too much overhead. Then, the initial question now gets a little bit transformed, resulting in the following:
How do you deliver all this value to your customers, using a single solution for all your models?
Let’s dive right into it!
NVIDIA Triton Inference Server
NVIDIA Triton Inference Server or just Triton - but not OpenAI Triton - is an open-source software that standardizes AI model deployment and execution across every workload. It enables teams to deploy AI models from multiple Deep Learning frameworks, and it supports a wide variety of configurations to tailor its performance to almost any given situation.
In future posts, we will go in-depth about how Triton works, but for now, a high-level architecture is enough. It is composed of the following elements:
- Model repository: It is where all the model objects are stored and uses a basic version tree system.
- HTTP server to process HTTP requests.
- gRPC server to process gRPC requests.
- C API: Can be queried directly or through the HTTP/gRPC servers.
- Schedulers and batchers: There are several types that can be used in a case-by-case scenario.
- Backends: Corresponding to the frameworks of the saved object models.
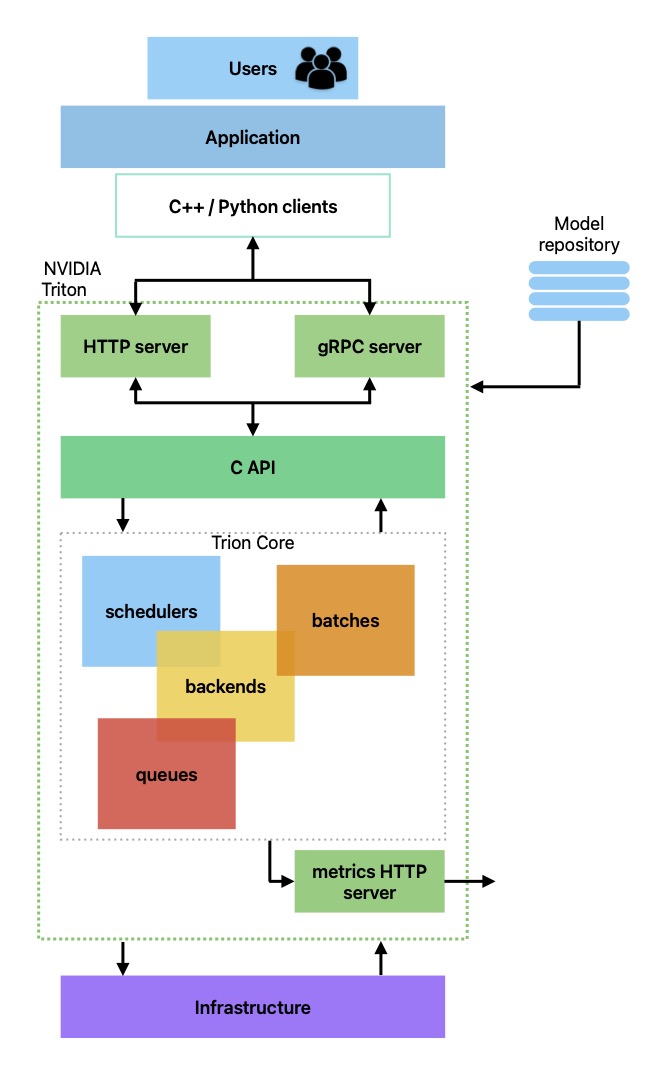
Depending on the backend, models are exported in one way or another, and the main backends for frameworks such as TensorFlow, PyTorch, and ONNX are already available, but a Python backend is also provided for custom backend needs.
Infrastructure
The idea behind having an inference server, apart from reasons such as having a standard way to deploy models and others, is to transfer the heavy computing in GPU to the server. Therefore, a solution to have a highly available, fault-tolerant, and scalable system is needed.
Here is where Nomad comes into play. Nomad is a simple and flexible scheduler and orchestrator for managing containers and non-containerized applications across on-prem and clouds at scale, similar to Kubernetes.
The keyword here is containers and how microservices architecture let us fly away the giant monoliths. It is vital that your images are optimized for performance so they are as lightweight as possible. Just for reference, a container image is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings. A container image becomes a container at runtime, and ideally it is an atomic part of your application, the smallest logic unit in terms a software package.
With a Nomad cluster, you can manage the number of instances of an app, i.e. container, how the deployment process occurs, control access to resources (GPU, CPU, RAM…), and it lets you scale really easily, among other things. Similarly, you can have several node pools, which are a way to group clients and segment infrastructure into logical units that can be targeted by jobs for strong control over where allocations are placed.
Conclusion
Providing value to your customers is a long and hard endeavor, and choosing the right tech stack for your use case will drastically ease your process. This is just an example of how it can be done, ending up in a highly available, fault-tolerant, scalable, and secure architecture that will be the backbone for all your applications. In the field of AI, things change really fast nowadays, and we might see a better solution for this particular problem in the future, but Triton is the de facto standard in the industry right now and that is undoubtable.